Aujourd’hui, les grandes entreprises et administrations publiques hésitent entre continuer à utiliser des logiciels propriétaires ou basculer vers les Logiciels Libres. Pourtant, la plupart des logiciels libres sont capables de bien traiter les données issues des logiciels propriétaire, et parfois avec une meilleur compatibilité.
C’est alors la barrière de la prise en main qui fait peur, et pourtant...
Les logiciels libres
L’aspect « Logiciel Libre » permet une évolution rapide et une plus grande participation des utilisateurs. Les aides et tutoriels foisonnent sur Internet ou sont directement inclus dans le logiciel lui-même.
Enfin, les concepteurs sont plus proches des utilisateurs, ce qui rend les logiciels libres plus agréable à utiliser et conviviaux.
Grâce à la disponibilité des logiciels libres, vous trouverez facilement des services de support techniques et la licence n’est plus un frein à l’utilisation de ces logiciels par votre personnel.
Notre support technique concerne essentiellement les logiciels libres, que ce soit sous forme de services ponctuels ou de tutoriels.
- Mars 2017 -
Cet article est le troisième d’une série de traductions d’articles écrits par Lin Clark et publiés sur le blog Hacks. La version anglaise est disponible ici. Merci à Jeremie et à goofy et Benjamin pour la relecture :) Si vous n’avez pas lu les autres articles, nous vous conseillons de démarrer depuis le début.
Pour comprendre comment WebAssembly fonctionne, il peut être utile de comprendre ce qu’est l’assembleur et comment les compilateurs le produisent.
Dans l’article sur la compilation à la volée (JIT), j’expliquais que communiquer avec une machine, c’était un peu comme communiquer avec un extraterrestre.

Nous allons maintenant voir comment ce cerveau extraterrestre fonctionne, comment la machine analyse et comprend ce qui lui est communiqué.
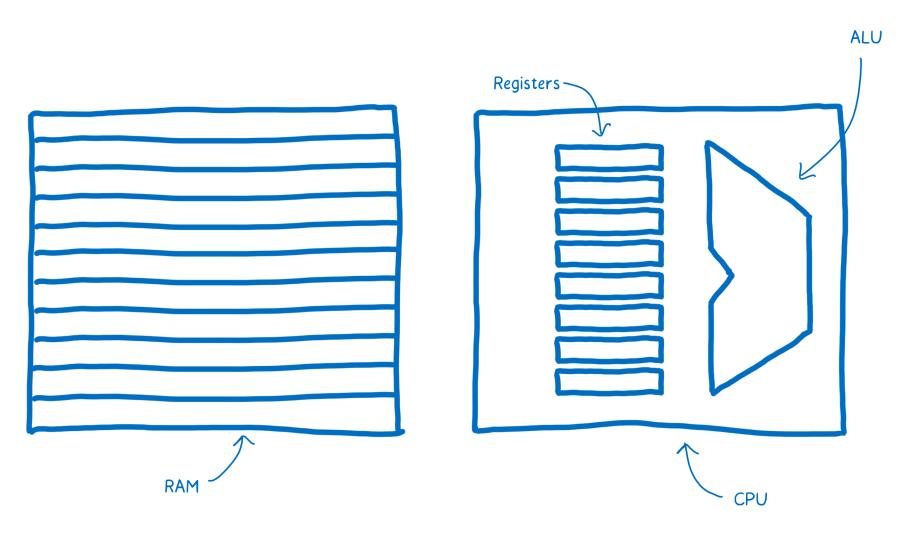
Une partie du cerveau est dédié à la réflexion (effectuer des additions, des soustractions, des opérations logiques). Il y a aussi non loin de là, une partie du cerveau qui fournit de la mémoire à court terme. Enfin, il y en a une dernière qui fournit de la mémoire à long terme.
Ces différentes parties ont chacune un nom :
- La partie dédiée à la réflexion est l’unité arithmétique et logique (UAL ou ALU en anglais).
- La mémoire à court terme est fournie par les registres.
- La mémoire à long terme est fournie par la mémoire vive (aussi appelée RAM en anglais pour Random Access Memory).
Les phrases formées par le code machine sont appelées des instructions.
Que se passe-t-il lorsqu’une de ces instructions parvient jusqu’au cerveau ? Elle est découpée en différentes parties qui ont chacune leur signification.
La façon dont cette instruction est découpée est propre au câblage de ce cerveau.
Ainsi, un cerveau câblé de cette façon prendrait toujours les six premiers bits pour les transmettre à l’UAL. L’UAL, en fonction de l’emplacement des zéros et des uns, comprendrait qu’il faut additionner deux trucs.
Ce morceau est appelé code de l’opération (ou « opcode » en anglais et dans le jargon informatique) car il indique à l’UAL l’opération qui doit être exécutée.
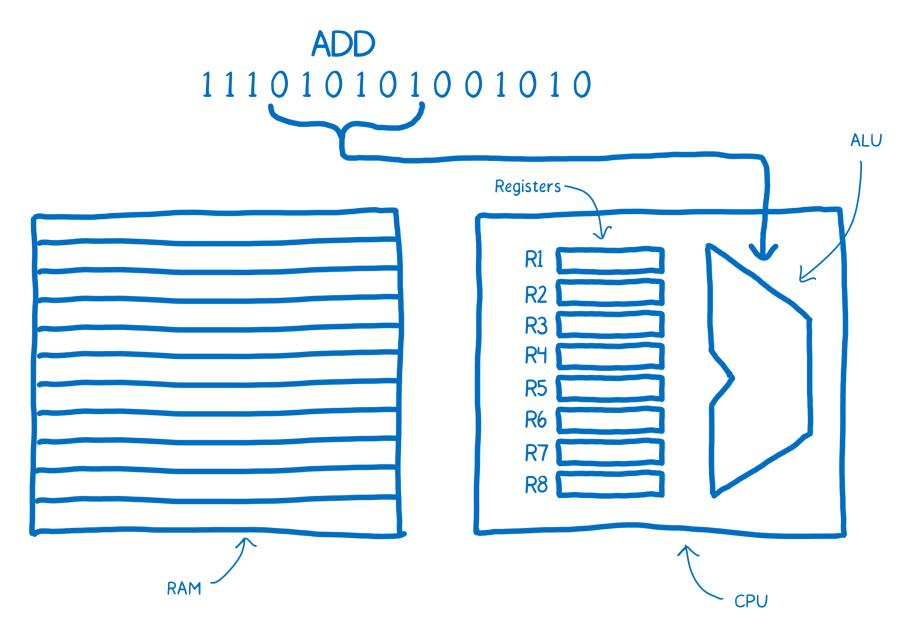
Ensuite, le cerveau prend les deux prochains morceaux, de trois bits chacun, afin de déterminer les nombres qu’il faut additionner. Ce sont les adresses des registres à utiliser.
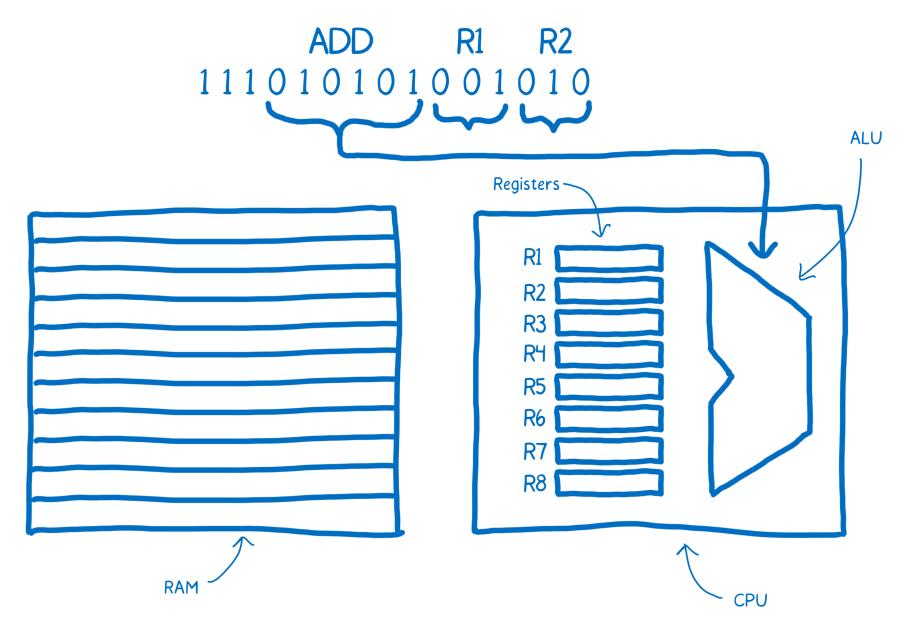
Vous voyez les annotations écrites au-dessus du code machine ? Elles sont ici pour nous aider, nous les humains, à mieux comprendre ce qui se passe. Ces annotations sont de l’assembleur. Ce sont des symboles mnémoniques qui permettent aux humains de donner du sens au code machine.
On peut voir ici qu’il existe une relation assez directe entre l’assembleur et le code machine de cette machine. À cause de cette relation, il existe différentes sortes d’assembleurs, chacun correspondant au type d’architecture d’une machine donnée. Lorsqu’on utilise une machine avec une architecture différente, il est fort probable qu’on ait besoin d’un autre « dialecte » d’assembleur.
Notre traduction ne vise donc pas une seule cible. Il n’existe pas de langue unique qui soit du code machine. Il existe différents codes machines. À l’instar de nous qui parlons différentes langues, les machines parlent différents codes.
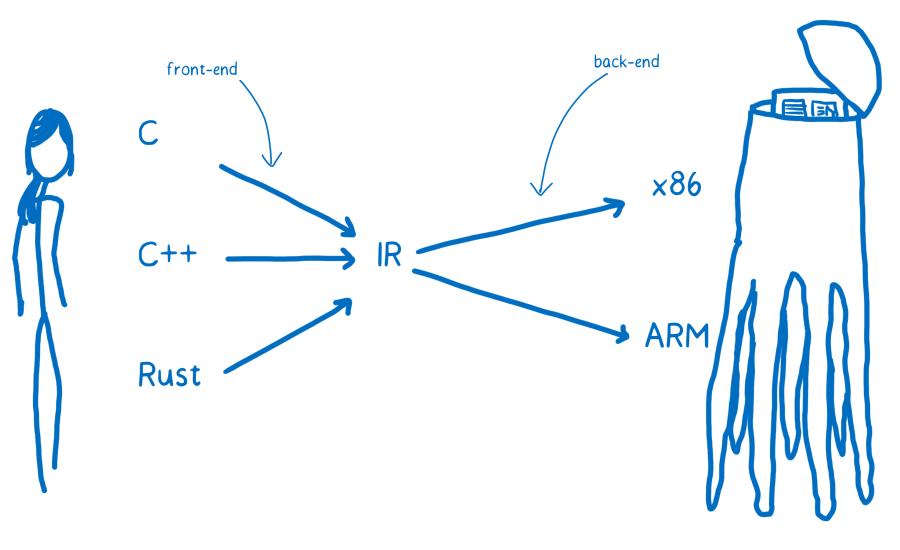
Pour la traduction humain-extraterrestre, on pourrait partir de l’anglais, du russe ou du mandarin comme langue source et le traduire en langue extraterrestre A ou en langue extraterrestre B. En programmation, on peut poursuivre l’analogie en partant d’un programme écrit en C ou en C++ ou en Rust et vouloir le traduire en x86 ou en ARM.
On veut être capable de traduire depuis n’importe lequel de ces langages de programmation de haut niveau vers n’importe lequel de ces langages assembleurs (dont chacun correspond à une architecture différente). Une solution à ce problème serait de créer un ensemble de traducteurs qui permettent de passer de chaque langage de programmation à chaque langage assembleur.
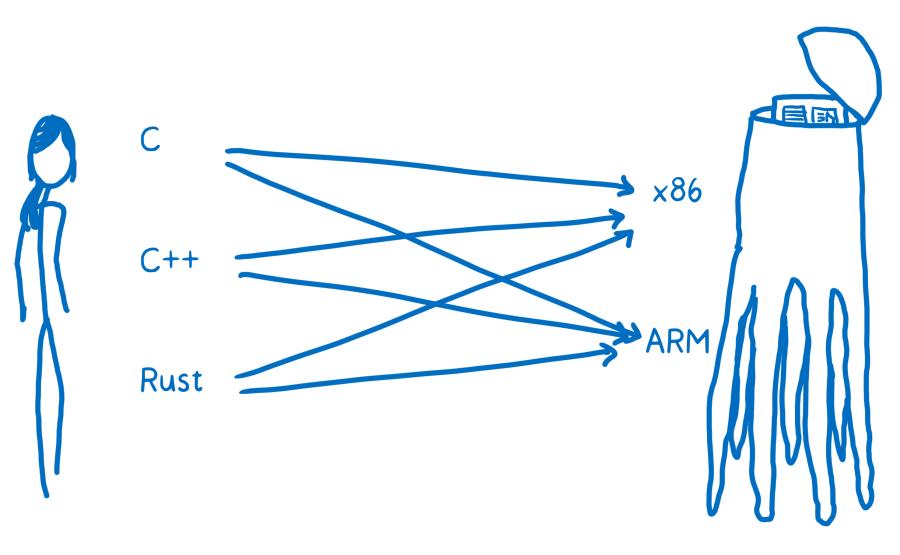
Ça se révèle plutôt inefficace. Pour résoudre ce problème, la plupart des compilateurs introduisent au moins une couche intermédiaire. Le compilateur prend en entrée le langage de programmation haut niveau et le traduit en quelque chose qui n’est ni un langage de haut niveau, ni du code machine. C’est ce qu’on appelle la représentation intermédiaire (RI ou IR en anglais).
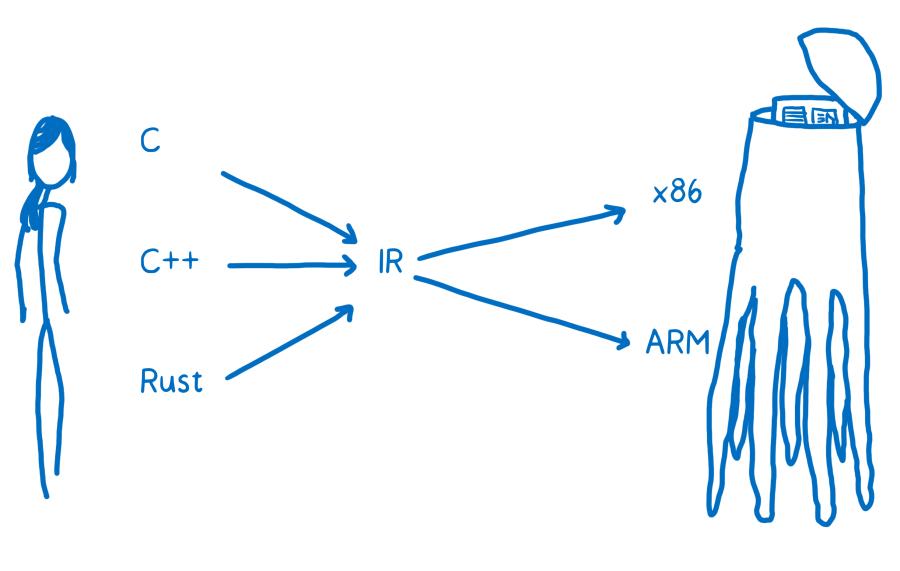
Ça signifie que le compilateur peut prendre n’importe lequel de ces langages de haut niveau et le traduire dans un des langages de RI. À partir de là, un autre composant du compilateur peut traiter cette RI et la compiler en quelque chose de plus spécifique à l’architecture cible.
La partie frontale du compilateur traduit le langage de programmation de haut niveau en RI et la partie en arrière-plan traite cette RI pour la transformer en code assembleur pour l’architecture cible.
Conclusion
Voici ce qu’est l’assembleur et comment les compilateurs traduisent des langages de programmation de haut niveau en assembleur. Dans le prochain article, nous verrons comment WebAssembly s’inscrit dans cet ensemble.
Lin est ingénieure au sein de l’équipe Mozilla Developer Relations. Elle bidouille avec JavaScript, WebAssembly, Rust et Servo et crée des bandes dessinées sur le code.